Vous trouverez ci-dessous les dernières activités et actualités du Master en STIC.
-
Réunion du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique »
Posté par
le
| Tags : conférence
Mise à jour du 17 avril 2024 : Il est désormais possible de consulter l’introduction par Isabelle Boydens ainsi que la présentation de Simon Hengchen. Merci à toutes et à tous pour votre participation.
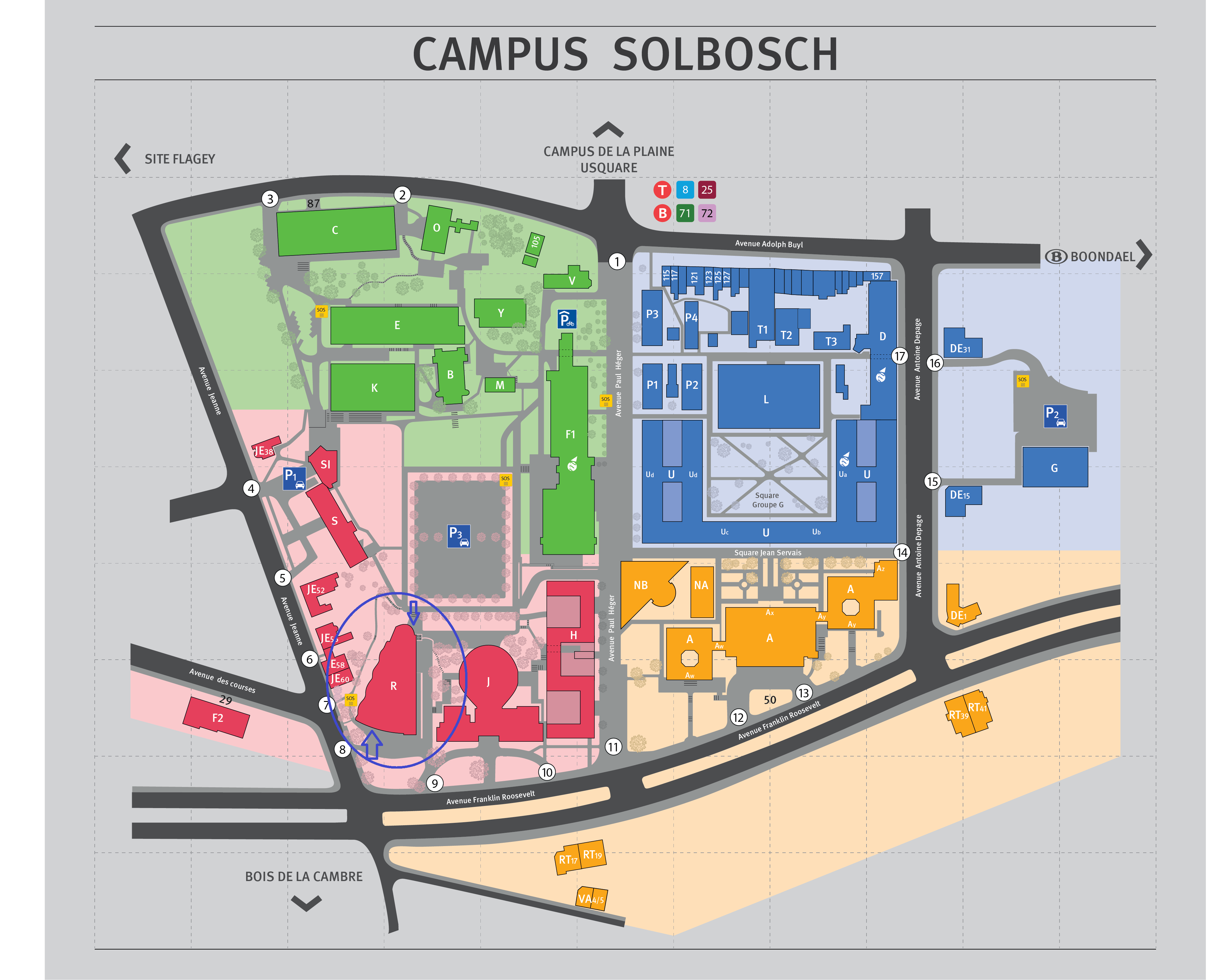
La prochaine réunion du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique » se tiendra le mardi 16 avril 2024 à 13h30 à l’Université libre de Bruxelles (auditoire R42.2.104, bâtiment R, campus du Solbosch). Le bâtiment et les accès sont signalés par un cercle et des flèches en bleu sur ce plan adapté du Solbosch.
Pluridisciplinaire, le groupe se situe au confluent des sciences appliquées et des sciences humaines et politiques. Le groupe, dont nous fêtons les 30 ans cette année, s’est réuni récemment en 2023.
La conférence sera présentée par Simon Hengchen, Docteur en Sciences et Technologies de l’Information et de la Communication de l’Université libre de Bruxelles, ses recherches se concentrent sur la détection du changement sémantique dans les textes historiques. Après avoir mené une carrière scientifique sur ce sujet en Suède et en Finlande, il est actuellement chargé d’enseignement à l’Université de Genève et consultant en TAL (Traitement automatique du langage).
La conférence cette année, “Approches quantitatives de textes historiques : quelques (non-) problèmes et comment les aborder ?” examinera, sur la base d’exemples concrets, les questions de qualité que soulève en TAL la reconnaissance optique des caractère (OCR) lorsqu’elle donne lieu à des résultats « erratiques ». Ce sujet, encore peu abordé, est en outre susceptible d’évoluer dans le temps, avec l’évolution des algorithmes et des langues traitées. Simon Hengchen posera le problème et indiquera des pistes concrètes afin d’y remédier.
La réunion se terminera par un débat suivi d’un drink. L’accès à la rencontre, qui est financée par le Fonds National de la Recherche Scientifique, est gratuit ; il est toutefois indispensable de s’inscrire avant le 9 avril 2024 au plus tard à l’événement via un formulaire en indiquant votre nom, prénom et institution(s) d’appartenance(*). Vous recevrez par email une confirmation d’inscription.
Programme
13h30 Introduction, par Isabelle Boydens, Présidente du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique », Professeur ordinaire à l’ULB et responsable du « Data Quality Competence Center » au sein du département Recherche de Smals
13h35 “Approches quantitatives de textes historiques : quelques (non-) problèmes et comment les aborder ? » par Simon Hengchen, Docteur en Sciences et Technologies de l’Information et de la Communication de l’Université libre de Bruxelles, chargé d’enseignement à l’Université de Genève et consultant en TAL (Traitement automatique du langage).
14h35 Débat et table ronde. Modérateurs : Max De Wilde, Docteur en Sciences et Technologies de l’Information et de la Communication de l’Université libre de Bruxelles, maître de conférences à l’Université libre de Bruxelles et à l’Université de Genève et consultant en TAL et Guillaume Quintin, doctorant en humanités numériques (laboratoire « Quantitative Digital Humanities ») et assistant scientifique au sein du Master en Sciences et Technologies de l’Information et de la Communication à l’Université libre de Bruxelles.
15h35 réception
Résumé
De manière parallèle à une consultation en archives, la recherche historique se fait également de manière quantitative, à travers l’utilisation d’archives numérisées et océrisées. Ce processus de reconnaissance optique de caractères (OCR) est souvent critiqué suite au bruit qu’elle introduit : si par exemple le mot « description » est mal reconnu et est retranscrit comme « defcription », comment une machine peut-elle correctement retrouver les documents ayant pour but de décrire un paysage, une oeuvre d’art, ou une personne ?
De l’autre côté du spectre, peu d’articles en traitement automatique des langues (TAL) mentionnent l’impact de ce bruit sur les diverses approches développées dans ce champ d’étude. Un algorithme développé pour de l’anglais du 21ème siècle fonctionnera-t-il aussi bien sur de l’anglais du 18ème, qui plus est de l’anglais présentant du bruit ?
Dans cette intervention, et ce à l’aide d’une étude de cas, nous tenterons de répondre de manière systématique à la question de l’impact de la qualité de l’information — dans ce cas-ci de l’information numérique sous forme de texte — sur plusieurs algorithmes de TAL bien connus des chercheurs et chercheuses en humanités numériques. Nous savons que le texte résultant d’un processus d’OCR n’est pas une parfaite représentation de la source originale : est-ce un problème ? Et si oui, pouvons-nous déterminer à partir de quel moment cela arrête d’en être un ?
Intervenant

Simon Hengchen est consultant en TAL et IA chez iguanodon.ai et chargé d’enseignement en TAL à l’Université de Genève, en Suisse. Titulaire d’un doctorat en Sciences et Technologies de l’Information et de la Communication de l’Université libre de Bruxelles, ses recherches se concentrent sur la détection du changement sémantique dans les textes historiques. Il a également été chercheur postdoctoral à Göteborgs universitet, en Suède, et à Helsingin yliopisto, en Finlande. Pour obtenir un aperçu complet de son parcours académique et de ses publications : https://hengchen.net.
(*)Réglementation en matière de protection des données :
Vous accédez à cette page et ces informations vous sont demandées car vous êtes repris sur une ou plusieurs listes de distribution par lesquelles l’Université libre de Bruxelles vous informe sur ses activités et/ou parce que vous vous inscrivez à un événement organisé par l’Université libre de Bruxelles. Le Règlement général sur la protection des données personnelles est entré en application le 25 mai 2018. L’ULB se conforme à cette législation et attache une grande importance à la protection de vos données à caractère personnel.
Ainsi, il vous est notamment possible, à tout moment, de vous désinscrire de cette invitation en envoyant un email à Guillaume.Quintin@ulb.be.
Dans tous les cas, sachez que l’Université n’utilise vos données que pour vous informer sur ses activités et qu’elle ne les communique pas à des tiers à des fins commerciales ou de marketing. Toutes vos questions sur la protection de vos données par l’ULB peuvent être envoyées à la Déléguée à la protection des données : rgpd@ulb.ac.be. Cette adresse est également celle par le biais de laquelle vous pouvez exercer vos droits en la matière : accès, rectification, effacement, limitation, opposition et portabilité.
-
Événement de la communauté STIC
Posté par
le
| Tags : conférenceAlumni, étudiants et membres de l’équipe enseignante se sont réunis ce 22 février pour écouter deux présentations :
- Guillaume Quintin a synthétisé son mémoire de Master, consacré à une étude stylométrique de l’œuvre de Gerbert d’Aurillac et lauréat du prix du meilleur mémoire STIC 2022-2023 ;
- Anthony Leroy, nouveau titulaire du cours de programmation et d’algorithmique I, a partagé un tour d’horizon sur la préservation des données sur le long terme, en particulier à l’ULB.
Les deux exposés ont suscité de riches discussions, qui ont ensuite laissé place à un moment convivial entre les participants autour d’un verre.

-
Atelier organisé par le MaSTIC à l’occasion de l’Après-midi inédit
Posté par
le
| Tags : conférenceCe mardi 20 février 2024, le Master a animé un atelier lors de l’Après-midi inédit organisé sur le campus du Solbosch : le temps d’un après-midi, les élèves de rhétorique ont pu découvrir l’Université et les matières qui y sont enseignées.
Sébastien de Valeriola et Guillaume Quintin ont proposé un atelier sur le thème de la stylométrie, intitulé : « La stylométrie : quand les statistiques et l’intelligence artificielle permettent d’identifier l’auteur d’une œuvre littéraire ».
Les supports utilisés lors de l’atelier sont accessibles ici :
- Dossier pédagogique (avec une bibliographie et une sitographie) ;
- Diapositives.

-
Réunion du groupe de contact FNRS « Les humanités des données »
Posté par
le
| Tags : conférenceLa deuxième réunion du groupe de contact FNRS « Les humanités des données », organisée par Nicolas Ruffini-Ronzani (UNamur et AÉN), Sébastien de Valeriola (ULB) et Paul Bertrand (UCLouvain), s’est déroulée le 6 novembre 2023.
Intitulée « Outils de visualisation, méthodes quantitatives et administration de la preuve en sciences humaines », cette réunion a rencontré un vif succès et provoqué de riches débats sur un sujet encore trop peu exploré.
Le programme peut être consulté sur l’affiche ci-dessous. Nous tâcherons de faire en sorte que les communications de chaque réunion du groupe de contact fassent l’objet d’une publication. L’article de la première réunion est sous presse et paraîtra bientôt (RBPH, 100, 2022, p. 925-939).

-
Slides de la séance d’accueil du 18/09/2023

{kind=link}
{kind=link}