Vous trouverez ci-dessous les dernières activités et actualités du Master en STIC.
-
Réunion du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique »
Posté par
le
| Tags : conférence
(Téléchargez l’introduction d’Isabelle Boydens et la présentation de Françoise Rossion.)
La prochaine réunion du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique » se tiendra le mercredi 12 mai 2021 de 14H à 15H30, elle aura lieu en ligne (vous recevrez le lien afin de rejoindre l’événement, une fois inscrits, voir ci-dessous).
Pluridisciplinaire, le groupe se situe au confluent des sciences appliquées et des sciences humaines et politiques.
Le groupe, dont nous avons fêté les 25 ans en 2019, s’est réuni récemment en 2020. La réunion de 2021 s’inscrira dans le thème fédérateur que l’Université libre de Bruxelles a choisi pour l’année académique 2020-2021, « les Citoyennetés numériques ». Un thème riche, entre autres, sur le plan social, politique, littéraire, culturel, cognitif ou encore, technologique.
En particulier, la conférence proposée lors de cette réunion du 12 mai 2021, « Avez-vous essayé l’ignorance ? Les défis du knowledge management aujourd’hui…», examinera, sur la base d’exemples issus des sciences humaines ou du monde des entreprises l’importance de la «gestion des connaissances». Et ce, dans le contexte de l’actualité que nous vivons, avec un accent sur la qualité des données. Plus d’information est disponible dans l’abstract ci-dessous.
La conférence sera présentée par Françoise Rossion, Présidente du Master en sciences et technologies de l’information et de la communication et Maître de Conférence à l’ULB ; elle est aussi chargée de cours à l’Université de Lille. En parallèle à ses activités d’enseignement, Françoise est consultante depuis plus de 25 ans en gestion des connaissances et a acquis une forte expérience tant dans le secteur public que privé, en Belgique et à l’étranger.
La réunion se terminera par une table ronde au cours de laquelle tous les participants qui le souhaitent seront invités à intervenir. L’accès à la rencontre, qui est financée par le Fonds National de la Recherche Scientifique, est gratuit ; il est toutefois indispensable de s’inscrire avant le 10 mai 2021 au plus tard à l’événement. Pour vous inscrire, veuillez envoyer un email à Mathias Coeckelbergs (mathias.coeckelbergs@ulb.be) en indiquant votre nom, prénom et institution(s) d’appartenance(*). Vous recevrez par email une confirmation d’inscription avec le lien Teams vous permettant de rejoindre l’événement du 12 mai.
Programme
14h00 Introduction, par Isabelle Boydens, Présidente du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique », Professeur ordinaire à l’ULB et responsable du « Data Quality Competence Center » au sein du département Recherche de Smals
14h05 « Avez-vous essayé l’ignorance ? Les défis du knowledge management aujourd’hui…», par Françoise Rossion
15h05 Débat et table ronde. Modérateur : Marc Borry, responsable du Knowledge Management auprès de l’Académie Nationale de Police et chargé de cours à l’Université de Lille.
Résumé
Avez-vous essayé l’ignorance ? Les défis du knowledge management aujourd’hui…
« La gestion des connaissances ? Projet trop cher, retour sur investissement non démontré ! » sont trop souvent les réponses données par les Directions d’entreprises qui, si elles sont conscientes d’une nécessité de « bien » gérer leurs connaissances, éprouvent encore des difficultés à articuler leurs besoins et à concrétiser leurs réflexions.
Souvent mal comprise, parfois décriée, ignorée, manipulée, la gestion des connaissances est une discipline relativement jeune qui se cherche toujours… Le sujet est pourtant fondamental : avons-nous le choix de « ne pas connaître » ou de « mal » connaître ? Pouvons-nous nous offrir le luxe de l’amnésie dans une économie imprévisible et toujours plus véloce, où la transformation digitale devient le maître mot ?
L’enjeu est pourtant de taille et l’actualité riche en exemples qui démontrent le « coût » à payer lorsque les décisions se fondent sur des données pertinentes : « La Lombardie, le cœur économique du nord de l’Italie, a été confinée et classée “zone rouge” à tort pendant une semaine en raison de statistiques régionales erronées » (23/01/2021).
Ce manque à gagner est aussi perceptible dans le cadre de nos pratiques professionnelles. Par exemple, le travail du restaurateur d’œuvres se base, en grande partie, sur son expérience et sur celles de ses prédécesseurs. Ces expériences lui permettent de prendre les « bonnes » décisions, de prévenir les problèmes et d’appliquer les pratiques les plus adéquates chaque fois que possible. L’avancée des connaissances en restauration et la possibilité de mettre en œuvre la meilleure solution dépendent cependant grandement de la motivation des restaurateurs à partager leurs expériences. La réalité montre que la transmission des « expériences négatives » reste sporadique, avec de trop rares témoignages sur les difficultés rencontrées et les apprentissages qui en découlent (https://journals.openedition.org/ceroart/1095).
L’objectif de cet exposé est d’expliquer et d’illustrer le nécessaire lien entre la gestion des connaissances et la qualité des données, mais aussi d’apporter un éclairage sur les défis de la mise en œuvre d’une telle démarche dans des organisations mises à mal par l’actualité sanitaire.
Cette actualité est pourtant riche en opportunités nouvelles, porteuse d’évolution et d’innovation. La gestion des connaissances n’y échappe pas puisqu’il est question de « Digital Knowledge Management ». En effet, la digitalisation des échanges et donc des partages de connaissances devient une priorité : est-ce possible cependant de considérer une numérisation de nos savoirs et savoir-faire sans les altérer ? Comment préserver la richesse de nos connaissances dans un contexte 100% digital ? Les réponses à ces interrogations légitimes sont multiples et multidisciplinaires, comme l’est la gestion des connaissances.
Intervenant

Françoise Rossion est Présidente du Master en sciences et technologies de l’information et de la communication et Maître de Conférence à l’ULB ; elle est aussi chargée de cours à l’Université de Lille. En parallèle à ses activités d’enseignement, Françoise est consultante depuis plus de 25 ans en gestion des connaissances et a acquis une forte expérience tant dans le secteur public que privé, en Belgique et à l’étranger. Elle est l’auteur de plusieurs articles et de deux ouvrages sur le sujet.
(*)Réglementation en matière de protection des données :
Vous accédez à cette page et ces informations vous sont demandées car vous êtes repris sur une ou plusieurs listes de distribution par lesquelles l’Université libre de Bruxelles vous informe sur ses activités et/ou parce que vous vous inscrivez à un événement organisé par l’Université libre de Bruxelles. Le Règlement général sur la protection des données personnelles est entré en application le 25 mai 2018. L’ULB se conforme à cette législation et attache une grande importance à la protection de vos données à caractère personnel.
Ainsi, il vous est notamment possible, à tout moment, de vous désinscrire de cette invitation en envoyant un email à Mathias.Coeckelbergs@ulb.ac.be
Dans tous les cas, sachez que l’Université n’utilise vos données que pour vous informer sur ses activités et qu’elle ne les communique pas à des tiers à des fins commerciales ou de marketing.Toutes vos questions sur la protection de vos données par l’ULB peuvent être envoyées à la Déléguée à la protection des données : rgpd@ulb.ac.be. Cette adresse est également celle par le biais de laquelle vous pouvez exercer vos droits en la matière : accès, rectification, effacement, limitation, opposition et portabilité.
-
Séance d’accueil
Posté par
le
| Tags : accueilChers futurs étudiants,
La filière du Master en Sciences et technologies de l’information et de la communication (MA-STIC) organise une séance d’accueil des nouveaux étudiants le jeudi 17 septembre à 18h00 au S.H1.301 (ULB Campus Solbosch, bâtiment H, niveau 1, local :H1.301). Il s’agit d’un grand auditoire, les règles de la distanciation seront respectées. Vous pouvez trouver le podcast de cette séance d’accueil ici, les slides ici.
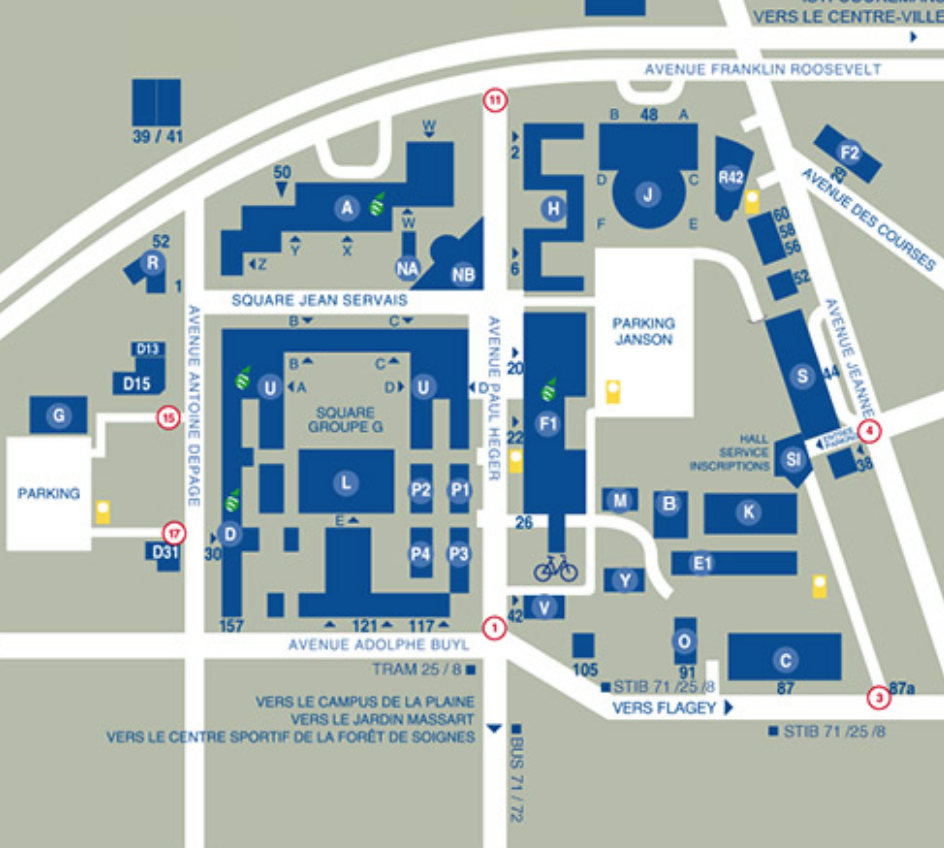
Veuillez trouver ci-dessous le plan du Campus Solbosch (https://www.ulb.be/fr/solbosch/plan-du-campus) :
Comment s’orienter? Les campus et bâtiments universitaires sont chacun désignés par une lettre de l’alphabet. Chaque local, auditoire ou bureau est référencé selon un code
Nom campus – bâtiment – porte d’entrée – niveau – numéro de la porte
Exemple : Campus du Solbosch – bâtiment U – porte D – niveau 3 – bureau 215 -> S.UD.3.215
Au plaisir de vous y retrouver!
-
Prix du CSA
Posté par
le
| Tags : prixAu printemps 2020, le « Prix du CSA » récompensera un mémoire de deuxième cycle de l’enseignement supérieur de type long (Master complémentaire et Master de spécialisation) d’un prix d’une valeur de 1 500 €.
Le prix sera décerné lors de la présentation du rapport annuel du CSA qui se déroulera le 22 avril 2020 devant tout le secteur de l’audiovisuel belge francophone réuni pour l’occasion.
Le mémoire doit constituer une contribution scientifique originale à la compréhension et à la réflexion sur les enjeux juridiques, économiques, sociologiques, politiques, culturels, technologiques ou créatifs de l’audiovisuel. Un mémoire fondé sur l’application de pratiques professionnelles est recevable à condition qu’il contribue à la réflexion scientifique sur ces mêmes enjeux. Il doit être impérativement transmis au CSA avant la date du 7 février 2020.
Veuillez trouver sous ce lien : une liste de sujets de mémoire en lien avec le secteur audiovisuel.
-
Présentation du MaSTIC – publication des slides
-
Réunion du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique »
Posté par
le
| Tags : conférenceTéléchargez les slides d’Isabelle Boydens et de Max De Wilde.
La prochaine réunion du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique » se tiendra le mercredi 29 janvier 2020 dès 13h30 à l’Université libre de Bruxelles (auditoire AY2.108, bâtiment A, campus du Solbosch). Pluridisciplinaire, le groupe se situe au confluent des sciences appliquées et des sciences humaines et politiques.
Le groupe, dont nous avons fêté les 25 ans en 2019, s’est réuni récemment en 2014, en 2015, en 2016, en 2017, en 2018 et en 2019. La réunion de 2020 s’inscrira dans le thème fédérateur que l’Université libre de Bruxelles a choisi pour l’année académique 2019-2020, « l’année des langues ». Un thème riche, entre autres, sur le plan littéraire, culturel, cognitif ou encore, technologique.
S’agissant des systèmes d’information et des technologies actuelles, la qualité des données, qui alimentent les programmes, est d’autant plus sensible que le langage naturel, toujours sujet à interprétation, évolue avec l’usage, de manière asynchrone d’une langue et d’une culture à l’autre.
En particulier, la conférence proposée lors de cette réunion du 29 janvier 2020, « I want to talk to a HUMAN! » : impact de la qualité des bases de connaissances sur les agents conversationnels, examinera cette question dans le domaine des agents conversationnels (ou « chatbots ») mobilisés pour assister les « centres de contacts ». Ceci, à travers une étude de cas particulièrement éclairante : celle du centre de contact de la Commission européenne, Europe Direct, qui traite annuellement près de 100.000 questions de citoyens formulées dans 23 langues. Nous verrons ensemble les défis que soulève l’implémentation d’un chatbot multilingue, devant répondre à des questions portant sur des domaines aussi variés que le Brexit, le programme de recherche Horizon 2020 ou les droits des passagers aériens, en mettant l’accent sur l’impact de la qualité des bases de connaissances sur les agents conversationnels.
La conférence sera présentée par Max De Wilde, Docteur en information et communication avec une spécialisation en linguistique computationnelle (Université libre de Bruxelles, 2015). En parallèle de son activité principale de consultant IT pour la Commission européenne, il est Maître de conférences à l’ULB où il dispense les cours de Traitement automatique de corpus et d’Ingénierie linguistique, ainsi que Chargé d’enseignement à l’Université de Genève.
La réunion se terminera par une table ronde au cours de laquelle tous les participants qui le souhaitent seront invités à intervenir. L’accès à la rencontre, qui est financée par le Fonds National de la Recherche Scientifique, est gratuit ; il est toutefois indispensable de s’inscrire avant le 23 janvier 2020 au plus tard à l’événement, le nombre de places disponibles étant limité. Accédez au formulaire d’inscription en cliquant ici.
Programme
13h30 Accueil des participants
14h00 Mot d’accueil par Seth Van Hooland, Chargé de cours à l’ULB et Président du Master en Sciences et Technologies de l’Information et de la Communication (MaSTIC)
14h05 Introduction, par Isabelle Boydens, Présidente du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique », Professeur ordinaire à l’ULB et responsable du « Data Quality Competence Center » au sein du département Recherche de Smals
14h15 “I want to talk to a HUMAN!” : impact de la qualité des bases de connaissances sur les agents conversationnels, par Max De Wilde
15h45 Débat et table ronde. Modérateur : Gani Hamiti, Data Quality Analyst chez Smals.
16h15 Réception
Résumé
“I want to talk to a HUMAN!” : impact de la qualité des bases de connaissances sur les agents conversationnels
Dans le secteur privé comme dans les administrations publiques, les agents conversationnels (« chatbots ») s’imposent progressivement comme support de première ligne permettant de fournir aux utilisateurs des réponses à leurs questions.
Pour ce faire, ces agents s’appuient sur des ressources internes ou externes pouvant prendre la forme de bases de connaissances structurées. La qualité de ces bases de connaissances, ainsi que celle de l’interprétation des requêtes formulées en langage naturel, a donc un impact direct sur les performances du système et la satisfaction de l’utilisateur.
Dans ce contexte, nous analyserons les forces et les limites du traitement automatique des langues et de l’apprentissage automatique pour la gestion de connaissances en constante évolution.
A cette fin, nous nous appuierons sur des exemples concrets issus du centre de contact Europe Direct de la Commission européenne (qui traite annuellement près de 100.000 questions de citoyens formulées dans 23 langues), et ce dans des domaines aussi divers que le Brexit, le programme de recherche Horizon 2020 ou encore les droits des passagers aériens.
Intervenant
 Max De Wilde est Docteur en information et communication avec une spécialisation en linguistique computationnelle (Université libre de Bruxelles, 2015). En parallèle de son activité principale de consultant IT pour la Commission européenne, il est Maître de conférences à l’ULB où il dispense les cours de Traitement automatique de corpus et d’Ingénierie linguistique, ainsi que Chargé d’enseignement à l’Université de Genève où il enseigne les TIC aux étudiants en traduction.
Max De Wilde est Docteur en information et communication avec une spécialisation en linguistique computationnelle (Université libre de Bruxelles, 2015). En parallèle de son activité principale de consultant IT pour la Commission européenne, il est Maître de conférences à l’ULB où il dispense les cours de Traitement automatique de corpus et d’Ingénierie linguistique, ainsi que Chargé d’enseignement à l’Université de Genève où il enseigne les TIC aux étudiants en traduction.